electra-italian-xxl-cased-squad-it
New Question Answering model for 🇮🇹 Italian language
It is an Electra model for Extractive Question Answering on Italian texts. I fine-tuned the pre-trained model dbmdz/electra-base-italian-xxl-cased-discriminator on SQuAD-it dataset.
Strengths 🏋️
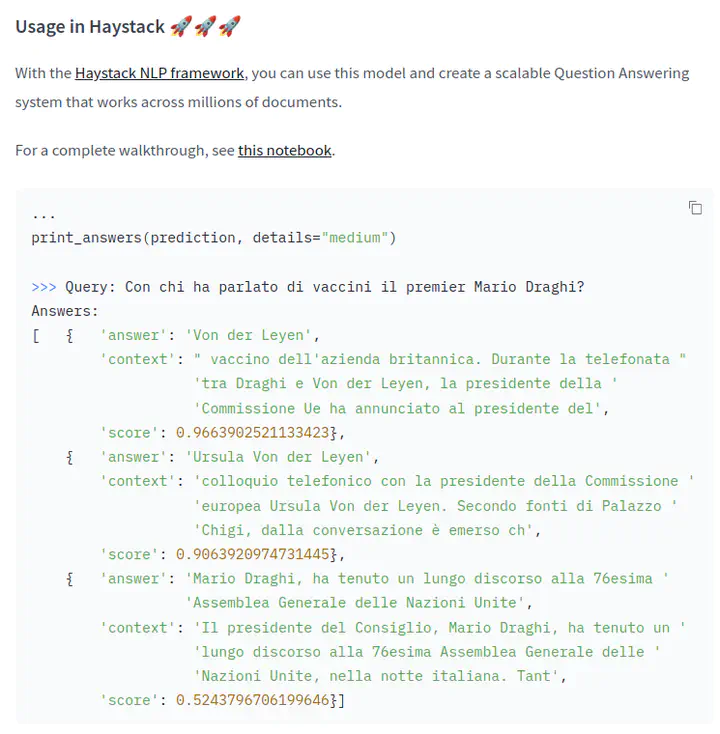
To date, the best publicly available model for Question Answering in Italian is it5/it5-large-question-answering by Gabriele Sarti and Malvina Nissim. Nevertheless, my model doesn’t work badly: it has a comparable F1 score and, thanks to the simpler architecture, it has a small size. anakin87/electra-italian-xxl-cased-squad-it also works out-of-the-box in the open-source Haystack NLP framework: you can use this model and create a scalable Question Answering system that works across millions of documents.
Challenges 🤔
As far as I know, models released by DBMZ in 2020 are the best base encoder models for the Italian language. Since then, more efficient architectures may have emerged (DeBERTa?), but training such models is costly and time-consuming so they are usually released by companies and institutions.
SQuAD-it is still a dataset of great relevance for the Italian language, but it is a human-curated translation of SQuAD1.1. Unlike SQuAD2.0, it does not contain unanswerable questions. A model trained in SQuAD1.1 always extracts some tokens from the context, representing an answer. It can’t say if a question is not answerable based on the context…